DeepSeekV4和GPT5.5谁更强 性能对决引发热议
DeepSeekV4和GPT5.5谁更强 性能对决引发热议。中国人工智能公司DeepSeek发布了全新系列模型DeepSeek-V4的预览版本,并同步开源。该系列模型在Agent能力、世界知识与推理性能三大维度上宣称达到国内及开源领域的领先水平。
DeepSeek-V4分为Pro和Flash两个版本,均支持百万(1M)token超长上下文,且大幅降低了对计算和显存的需求。API服务也已上线,开发者只需将model参数修改为deepseek-v4-pro或deepseek-v4-flash即可调用,接口兼容OpenAI ChatCompletions与Anthropic两套标准。
由于高端算力供给限制,目前Pro版本的服务吞吐量有限,但预计下半年随着华为昇腾950超节点批量上市后,Pro版本的价格将大幅下调。昇腾CANN将在16点直播DeepSeek V4在昇腾平台的首发。
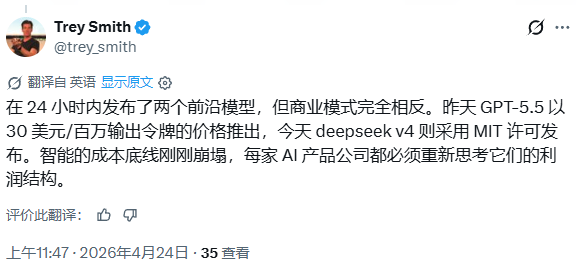
此次发布与OpenAI前一天推出的GPT-5.5几乎同步。两款产品定价策略截然不同。有网友指出,GPT-5.5以每百万输出token 30美元的价格上线,而DeepSeek V4则以MIT许可证开源发布,这使得AI智能的成本底线发生了变化,每一家AI产品公司都不得不重新审视自己的利润结构。网友Enrico评价称DeepSeek V4快速且智能,但他认为每百万token 3.48美元的输出价格并不便宜,不过LocalAI将推动该模型面向更广泛用户群体普及。
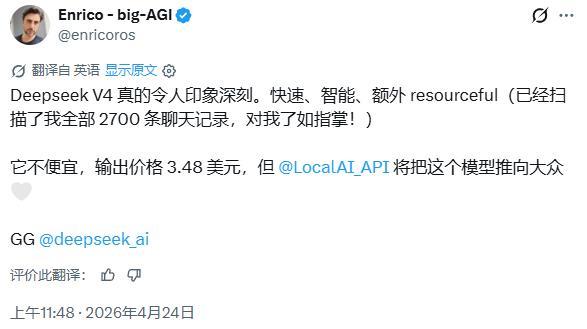
DeepSeek-V4-Pro是本次发布的旗舰版本,官方将其定位为性能比肩顶级闭源模型。在数学、STEM及竞赛型代码评测中,V4-Pro宣称超越当前所有已公开评测的开源模型,并取得比肩世界顶级闭源模型的成绩。在世界知识评测方面,V4-Pro大幅领先其他开源模型,仅稍逊于Google的Gemini-Pro-3.1。相比前代模型,DeepSeek-V4-Pro的Agent能力显著增强,在Agentic Coding评测中达到当前开源模型最佳水平。目前DeepSeek-V4已成为公司内部员工使用的Agentic Coding模型,据评测反馈使用体验优于Sonnet 4.5,交付质量接近Opus 4.6非思考模式,但仍与Opus 4.6思考模式存在一定差距。
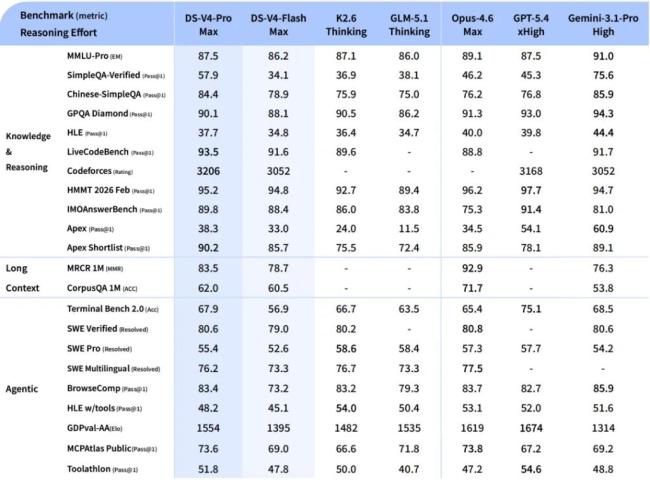
DeepSeek-V4-Flash定位为更快捷、经济的轻量化选项。相比DeepSeek-V4-Pro,DeepSeek-V4-Flash在世界知识储备方面稍逊一筹,但在推理能力上表现出色。由于模型参数与激活规模较小,其API服务在速度与成本上具备明显优势。在Agent评测中,V4-Flash在简单任务上与V4-Pro表现相当,但在高难度任务上仍有差距。这一定位使V4-Flash更适合对延迟和成本敏感、任务复杂度适中的企业级应用场景。
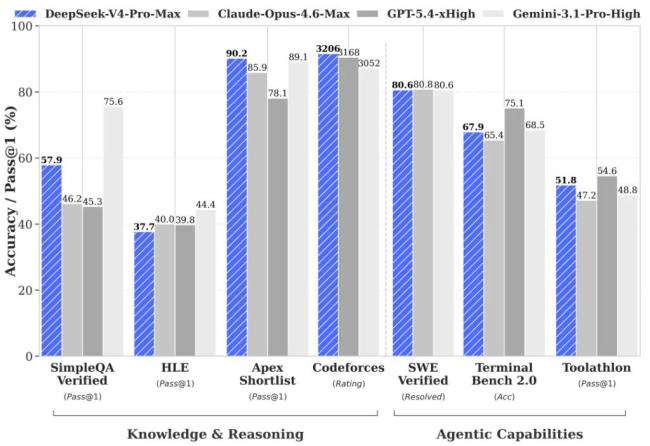
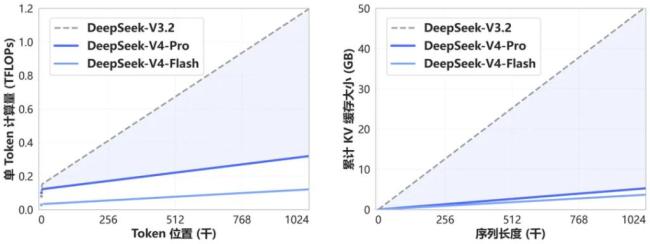
DeepSeek-V4在底层架构上引入了一种全新的注意力机制,在token维度进行压缩,并结合自研DSA稀疏注意力技术,实现了全球领先的长上下文能力,同时大幅降低了对计算资源和显存的需求。这一创新使得1M上下文窗口成为DeepSeek所有官方服务的标配。对于需要处理长文档、长对话或复杂多步骤任务的企业用户而言,这一能力的普及具有实质性意义。降低算力消耗的同时扩展上下文窗口,也有助于进一步压低推理成本,强化DeepSeek在性价比维度的竞争优势。

DeepSeek表示,V4系列针对Claude Code、OpenClaw、OpenCode、CodeBuddy等主流Agent产品进行了专项适配与优化,在代码任务及文档生成任务上均有性能提升。API层面,两款模型最大上下文长度均为1M,同时支持非思考模式与思考模式。思考模式通过reasoning_effort参数设定推理强度,可选high或max档位。DeepSeek建议,针对复杂Agent场景应启用思考模式并将强度设为max。